任何抛开场景对设计进行的评价都是愚蠢的。一个方案只要能实现目的都叫解决方案,解决方案没有对错,但是有好坏,我这里会总结一些我们在开发过程中所做的一些不好的设计、编码,包括管理方面愚蠢的举动。我会对入围的bad case进行场景的剖析,分析当时我们为什么会这么想,当然有些是我在采访当事人之后他们给出的说法。
try catch系列
for 循环内 try catch
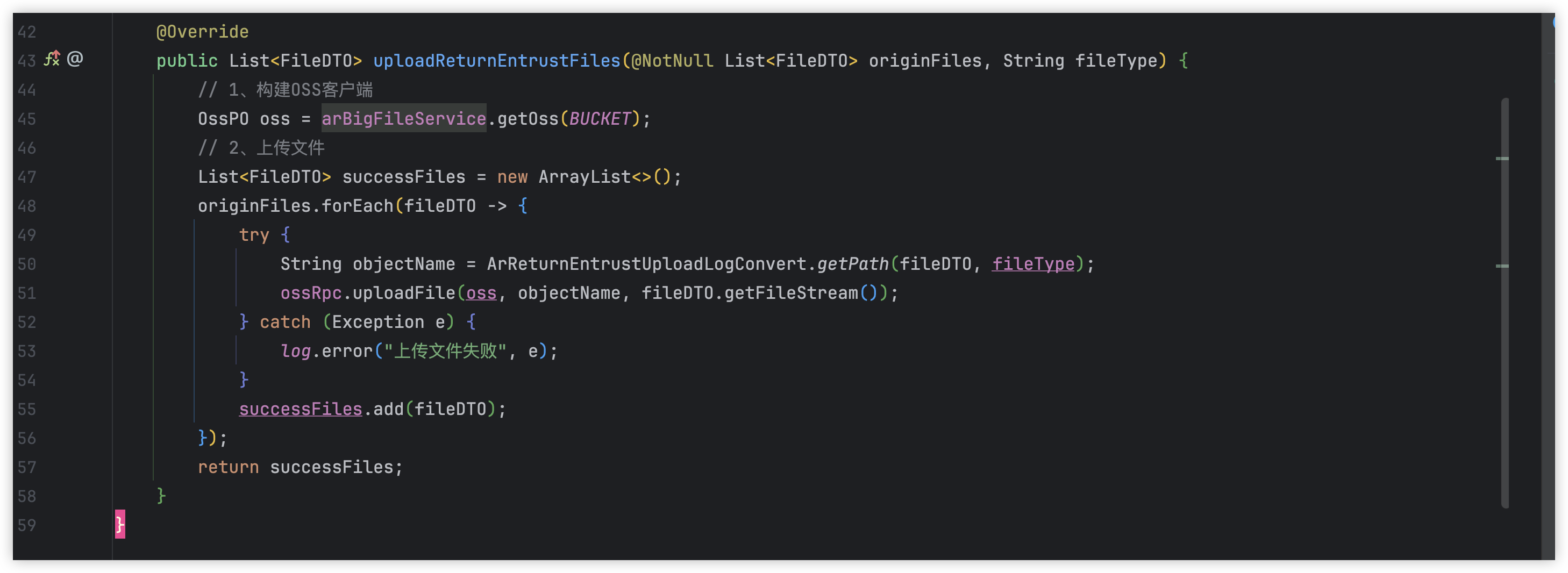
这里本意是 forEach 针对每一个元素进行一个操作,该操作有可能会抛出异常,为了在for循环中不阻塞后面元素的执行,因此这里进行了try catch。一旦对元素的处理成功就加到一个成功的集合中并在最后进行返回。
但是,这里忽略了一点,就是失败的数据也被认为是成功的给加入到成功的list中进去了。
修改方式之一:
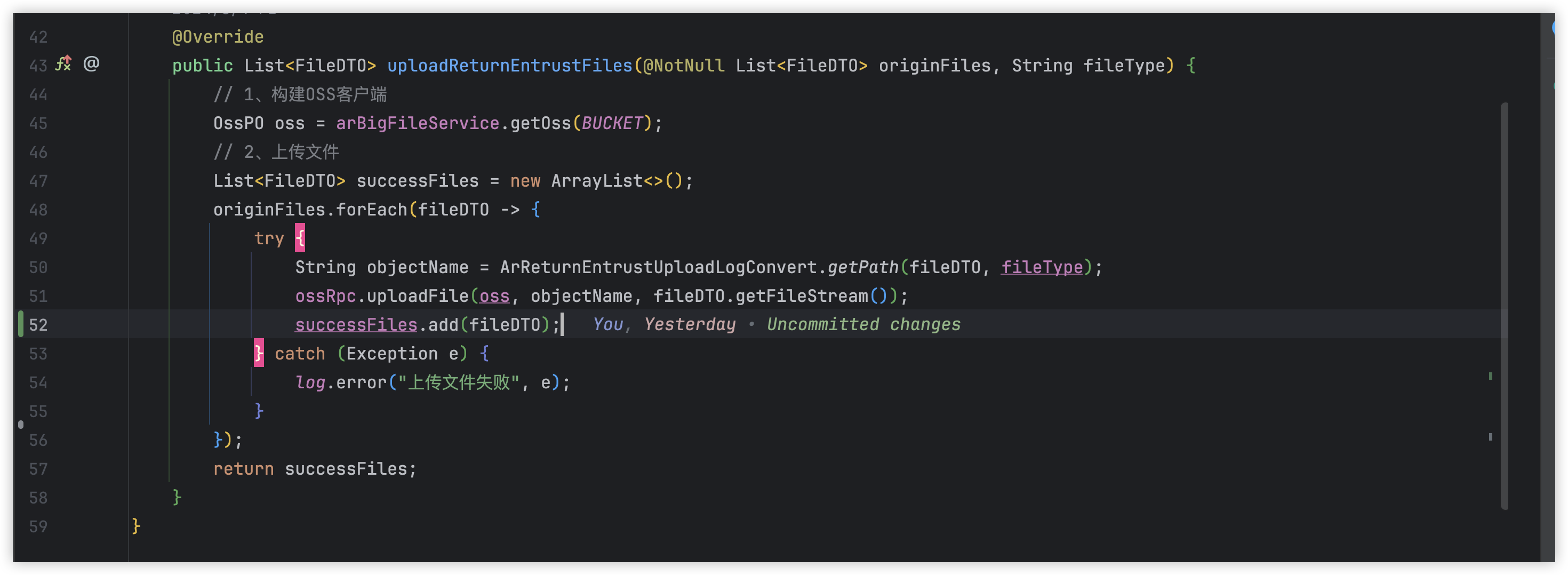
finally 当中抛出异常
public Boolean update( PmAssetUpdateLogicForm pmAsset) {
ResponseInfo<Boolean> responseInfo = null;
try {
FeignContext.setCustomHeader(CommonConstants.TENANT_HEADER, TenantContext.getTenantId());
responseInfo = assetInnerApi.update(pmAsset);
Preconditions.checkArgument(HttpStatus.HTTP_OK == responseInfo.getStatusCode(), ERR_MSG_PRE + responseInfo.getMessage());
return responseInfo.getData();
} catch (Exception e) {
throw new RuntimeException(ERR_MSG_PRE + e.getMessage(), e);
} finally {
log.info("更新资产包信息 assetInnerApi.update with PmAssetUpdateLogicForm:{} => update:{}", pmAsset, responseInfo.getData());
}
}在 Java 中,如果 finally 块中抛出异常,它会影响 catch 块中的异常处理方式。让我解释一下具体的行为:
如果 try 块中没有抛出异常,但在 finally 块中抛出了异常,则该异常会向上传播,就像正常情况下一样。
如果 try 块中抛出了异常,并且 catch 块捕获了该异常,但随后 finally 块也抛出了异常:
finally 块中的异常会覆盖原来被 catch 块捕获的异常
原来的异常会被抑制(suppressed),程序最终只会看到 finally 块抛出的异常
如果 catch 块本身又抛出了一个新的异常,而 finally 块也抛出异常:
同样地,finally 块中的异常会覆盖之前的所有异常
mysql 系列
java中自定义的sql有必要全部大写么
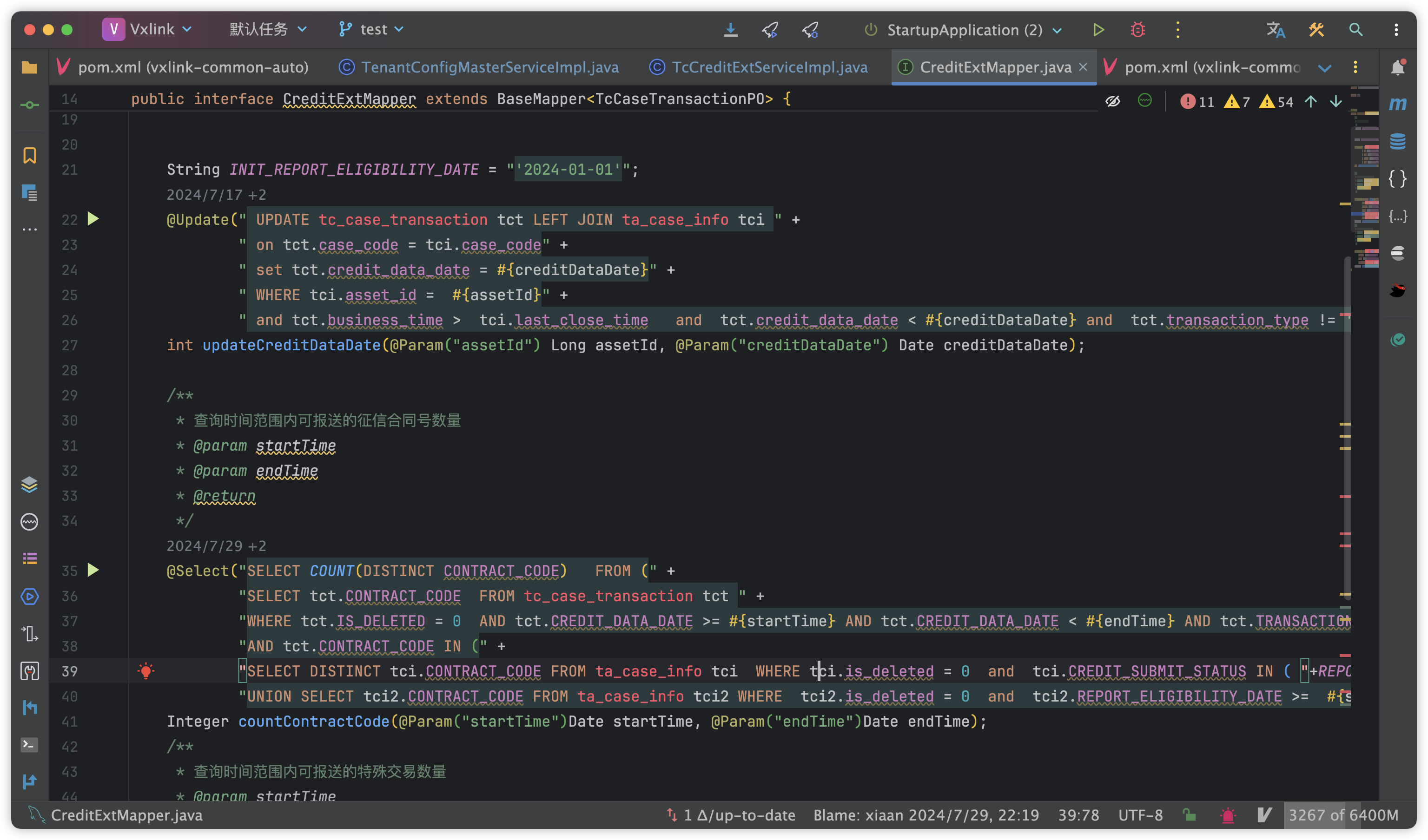
有同事写代码的时候,特意把sql语句全部大写了。说是Mysql会默认转大写,如果全部写了大写就不用转了,提高性能。
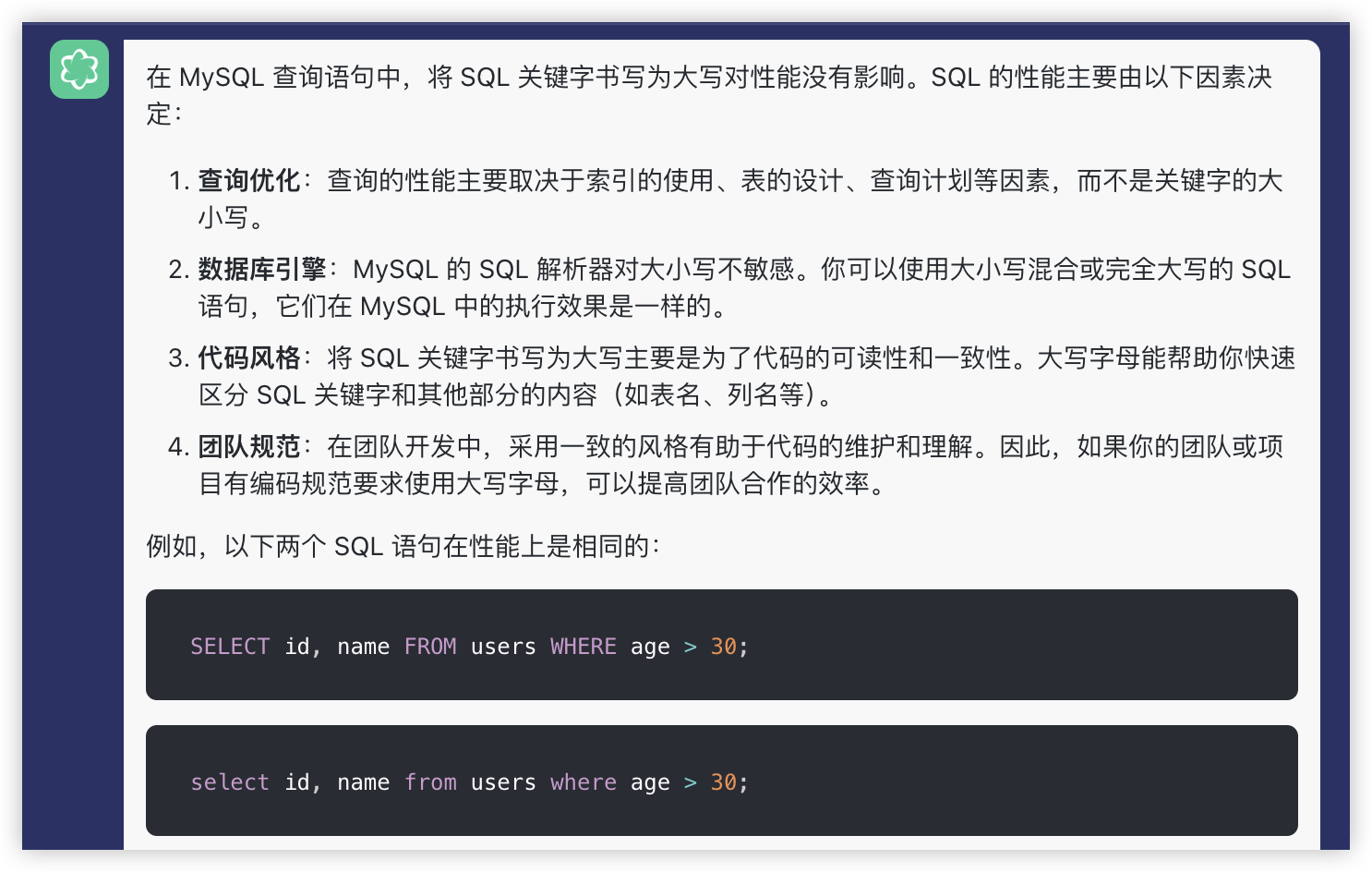
网上的文章有的说可以提升性能,但是我问了一下Chat,回答如下,自己评判吧
CompletableFuture 系列
exceptionally 判断 e 是否为空
// exceptionally 中捕获判断 e 是否为空
public CompletableFuture<Boolean> addSealOneAsync(Object o, SealTypeEnum sealTypeEnum, String otherTemplateId, String batchCode) {
String tenantId = TenantContext.getTenantId();
return CompletableFuture.supplyAsync(() -> {
TenantContext.setTenantId(tenantId);
return addSealOne(o, sealTypeEnum, otherTemplateId, batchCode);
}, threadPoolComponent.getSealGroupThreadPool()).exceptionally(e -> {
if (e != null) {
// 记录日志
log.error("电子印章盖章异步任务异常。证明材料:{},印章类型:{},其他模板ID:{},批次号:{}", o, sealTypeEnum, otherTemplateId, batchCode, e);
}
return false;
});
}首先,CompletableFuture 的 .exceptionally 注册的函数其本意是 当.supplyAsync发生异常的时候需要执行的方法,并且这个方法需要明确一下在异常时候的返回值。也就是说这个.exceptionally本意就是再遇到异常的时候给程序一个默认值,而不要再抛出异常。所以 e 一定不为空,这里判空是如此一举的。如下,直接记录日志并返回默认值即可。
public CompletableFuture<Boolean> addSealOneAsync(Object o, SealTypeEnum sealTypeEnum, String otherTemplateId, String batchCode) {
String tenantId = TenantContext.getTenantId();
return CompletableFuture.supplyAsync(() -> {
TenantContext.setTenantId(tenantId);
return addSealOne(o, sealTypeEnum, otherTemplateId, batchCode);
}, threadPoolComponent.getSealGroupThreadPool()).exceptionally(e -> {
// 记录日志
log.error("电子印章盖章异步任务异常。证明材料:{},印章类型:{},其他模板ID:{},批次号:{}", o, sealTypeEnum, otherTemplateId, batchCode, e);
return false;
});
}exceptionally 捕获并抛出一个RuntimeException异常
//exceptionally 捕获并抛出一个RuntimeException异常
private CompletableFuture<Map<String, byte[]>> asyncDownloadOssFile(@NotNull OssPO oss, @NotBlank String fileName, @NotBlank String dir) {
return CompletableFuture.supplyAsync(() -> {
Map<String, byte[]> resultMap = new HashMap<>();
resultMap.put(fileName, ossRpc.downloadRaw(oss, dir + fileName));
return resultMap;
}, threadPoolComponent.getArchiveThreadPool()).exceptionally(e -> {
if (e != null) {
throw new RuntimeException("异步下载文件失败!错误信息:" + e.getMessage(), e);
}
return null;
});
}首先,CompletableFuture 的 .exceptionally 注册的函数其本意是 当.supplyAsync发生异常的时候需要执行的方法,并且这个方法需要明确一下在异常时候的返回值。也就是说这个.exceptionally本意就是再遇到异常的时候给程序一个默认值,而不要再抛出异常。所以 e 一定不为空,这里判空是如此一举的。 那你说我不判空了,我按照下面这么写。
private CompletableFuture<Map<String, byte[]>> asyncDownloadOssFile(@NotNull OssPO oss, @NotBlank String fileName, @NotBlank String dir) {
return CompletableFuture.supplyAsync(() -> {
Map<String, byte[]> resultMap = new HashMap<>();
resultMap.put(fileName, ossRpc.downloadRaw(oss, dir + fileName));
return resultMap;
}, threadPoolComponent.getArchiveThreadPool()).exceptionally(e -> {
throw new RuntimeException("异步下载文件失败!错误信息:" + e.getMessage(), e);
return null;
});
}这种写法连编译都通不过。因此你说那我再遇到异常的之后直接抛出一个RuntimeException,不写返回值了,这样总不会错了吧。当然编译不会出错,但是本来人家就抛出一个RuntimeException异常,你捕获了之后又抛出了一个RuntimeException异常,这不多此一举了么
private CompletableFuture<Map<String, byte[]>> asyncDownloadOssFile(@NotNull OssPO oss, @NotBlank String fileName, @NotBlank String dir) {
return CompletableFuture.supplyAsync(() -> {
Map<String, byte[]> resultMap = new HashMap<>();
resultMap.put(fileName, ossRpc.downloadRaw(oss, dir + fileName));
return resultMap;
}, threadPoolComponent.getArchiveThreadPool()).exceptionally(e -> {
throw new RuntimeException("异步下载文件失败!错误信息:" + e.getMessage(), e);
});
}这种写法,跟线面这种不写 exceptionally的写法本质上没有什么区别。所以结论就是,exceptionally 捕获并抛出一个RuntimeException异常 这种做法没有意义,可以不写。
private CompletableFuture<Map<String, byte[]>> asyncDownloadOssFile(@NotNull OssPO oss, @NotBlank String fileName, @NotBlank String dir) {
return CompletableFuture.supplyAsync(() -> {
Map<String, byte[]> resultMap = new HashMap<>();
resultMap.put(fileName, ossRpc.downloadRaw(oss, dir + fileName));
return resultMap;
}, threadPoolComponent.getArchiveThreadPool());
}如果非要较真,区别就是再捕获异常之后再异常的message中加了一个 "异步下载文件失败!错误信息:" 但这个信息对定位问题并没有给程序定位带来多大的帮助。如果这里不抛出一个RuntimeException而是抛出一个特定的自定义异常,然后再上层针对这个自定义的异常进行一个业务逻辑的处理,我还能接受,否则这里没有必要捕获这个异常。当然还有一个前提是,在外层调用这个一步方法之后,需要有join或者get方法,否则不捕获异常打印日志的行为会导致异常堆栈的丢失。
抽象类中使用 @Resource 以及 SpringUtil.getBean
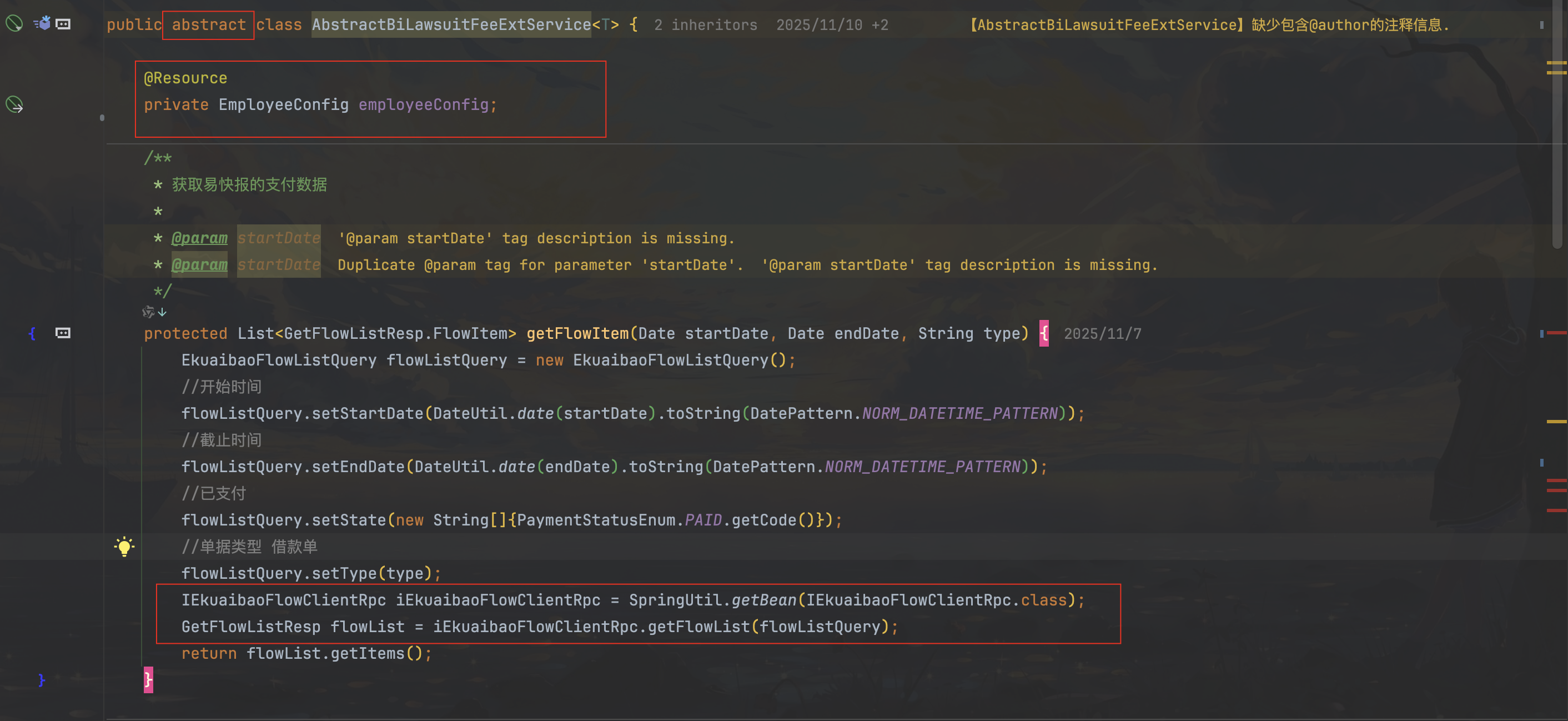
public abstract class AbstractBiLawsuitFeeExtService<T> {
@Resource
private EmployeeConfig employeeConfig;
/**
* 获取易快报的支付数据
*
* @param startDate 开始时间
* @param endDate 结束时间
* @param type 类型
* @return 流程项列表
*/
protected List<GetFlowListResp.FlowItem> getFlowItem(Date startDate, Date endDate, String type) {
EkuaibaoFlowListQuery flowListQuery = new EkuaibaoFlowListQuery();
//开始时间
flowListQuery.setStartDate(DateUtil.date(startDate).toString(DatePattern.NORM_DATETIME_PATTERN));
//截止时间
flowListQuery.setEndDate(DateUtil.date(endDate).toString(DatePattern.NORM_DATETIME_PATTERN));
//已支付
flowListQuery.setState(new String[]{PaymentStatusEnum.PAID.getCode()});
//单据类型 借款单
flowListQuery.setType(type);
IEkuaibaoFlowClientRpc iEkuaibaoFlowClientRpc = SpringUtil.getBean(IEkuaibaoFlowClientRpc.class);
GetFlowListResp flowList = iEkuaibaoFlowClientRpc.getFlowList(flowListQuery);
return flowList.getItems();
}
}上面的代码是两个队员写的,他们其实遇到了同一个问题,那就是在抽象类中遇到需要使用外部servcie的方法。
在 Spring Boot 中,抽象类无法被直接实例化(因此不能通过 @Component/@Service 等注解注册为 Bean),但抽象类的子类可以被 Spring 管理。基于这一特性,抽象类中依赖注入 Service 的核心思路是:在抽象类中定义依赖(Service),由其子类(被 Spring 管理的 Bean)通过 “构造器注入” 或 “字段注入” 传递依赖,最终实现抽象类对 Service 的复用。
那如果一个抽象类遇到了,需要使用某个service的情况改怎么办呢?
推荐实现方式:构造器注入(首选)
Spring 官方推荐构造器注入(显式声明依赖、避免空指针、支持不可变字段),抽象类中通过构造器接收 Service,子类在自己的构造器中注入 Service 并传递给父类(抽象类)。这种方式最规范、可测试性最强。
步骤示例:
- 抽象类:定义构造器,接收需要依赖的 Service;
- 子类:标注 @Service/@Component 成为 Spring Bean,在自身构造器中注入 Service,并调用父类构造器传递依赖;
- 抽象类的方法即可直接使用注入的 Service。
正确的写法示例:
// 1. 抽象类:定义依赖(Service),通过构造器接收
public abstract class AbstractBaseService {
// 抽象类中依赖的 Service(不可变,用 final 修饰更安全)
protected final UserService userService;
protected final OrderService orderService;
// 抽象类的构造器:接收子类传递的 Service
public AbstractBaseService(UserService userService, OrderService orderService) {
this.userService = userService;
this.orderService = orderService;
}
// 抽象类的通用方法:直接使用注入的 Service
public void commonMethod(Long userId) {
// 复用 userService:获取用户信息
User user = userService.getUserById(userId);
// 复用 orderService:查询用户订单
List<Order> orders = orderService.getOrdersByUserId(userId);
// 子类可扩展的逻辑(抽象方法)
doBusiness(user, orders);
}
// 抽象方法:由子类实现具体业务逻辑
protected abstract void doBusiness(User user, List<Order> orders);
}
// 2. 子类:Spring Bean,构造器注入 Service 并传递给父类
@Service // 子类是 Spring 管理的 Bean
public class UserOrderService extends AbstractBaseService {
// 子类构造器:注入 Service,调用父类构造器传递依赖
@Autowired // Spring 会自动注入 UserService 和 OrderService
public UserOrderService(UserService userService, OrderService orderService) {
// 必须调用父类构造器,将 Service 传递给抽象类
super(userService, orderService);
}
// 实现抽象方法:具体业务逻辑
@Override
protected void doBusiness(User user, List<Order> orders) {
// 子类自定义逻辑,可直接使用父类的 userService/orderService
System.out.println("用户:" + user.getName() + " 的订单数:" + orders.size());
}
}优点:
- 显式依赖:子类构造器明确声明依赖,符合 Spring 设计原则;
- 不可变安全:抽象类的 Service 用 final 修饰,避免子类意外修改;
- 可测试性:单元测试时,可直接通过子类构造器传入 Mock 的 Service(无需启动 Spring 容器)。
备选方式:字段注入(不推荐,仅适用于简单场景)
若抽象类的子类较多,且依赖的 Service 数量少,也可通过 “子类字段注入 + 抽象类 protected 字段” 的方式实现,但这种方式存在依赖隐藏、不可变缺失等问题,仅建议在简单场景下使用。
步骤示例:
- 抽象类定义 protected 修饰的 Service 字段(非 final);
- 子类(Spring Bean)通过 @Autowired 注入 Service,并赋值给父类字段。
// 1. 抽象类:定义 protected 字段接收依赖
public abstract class AbstractBaseService {
// protected 字段:由子类注入后赋值
protected UserService userService;
protected OrderService orderService;
// 抽象类通用方法:使用依赖
public void commonMethod(Long userId) {
User user = userService.getUserById(userId); // 直接使用子类注入的依赖
List<Order> orders = orderService.getOrdersByUserId(userId);
doBusiness(user, orders);
}
protected abstract void doBusiness(User user, List<Order> orders);
}
// 2. 子类:注入 Service 并赋值给父类字段
@Service
public class UserOrderService extends AbstractBaseService {
// 子类字段注入:Spring 注入后,赋值给父类的 protected 字段
@Autowired
public void setUserService(UserService userService) {
this.userService = userService; // this 指向子类,父类字段随之赋值
}
@Autowired
public void setOrderService(OrderService orderService) {
this.orderService = orderService;
}
@Override
protected void doBusiness(User user, List<Order> orders) {
// 业务逻辑
}
}缺点:
- 依赖隐藏:抽象类的依赖未在构造器中声明,开发者需查看子类代码才能知道依赖来源;
- 不可变风险:Service 字段非 final,子类可能意外修改字段值,导致空指针或逻辑错误;
- 测试困难:若子类未提供 Setter 方法,单元测试时无法手动注入 Mock 依赖。
关于 getBean 这种写法的分析
一、破坏 Spring 依赖注入的 “解耦” 设计原则
Spring 的核心优势之一是依赖注入(DI):通过容器统一管理 Bean 的创建和依赖关系,开发者无需手动 “查找” 或 “创建” 依赖(即 “控制反转 IOC”),实现组件间的解耦。
而 SpringUtil.getBean() 是典型的 “主动查找依赖” 模式,相当于开发者手动从容器中 “拉取” Bean,而非让 Spring 主动 “推送” 依赖。这种写法会导致:
- 抽象类 AbstractBiLawsuitFeeExtService 与 SpringUtil 强耦合:代码必须依赖 Spring 容器才能运行,脱离 Spring 环境(如单元测试)则直接失效;
- 依赖关系 “隐藏”:从类的成员变量或构造方法中,无法直观看到 IEkuaibaoFlowClientRpc 是该类的依赖(依赖关系不在类定义中显式声明),其他开发者阅读代码时需要深入方法内部才能发现,降低可读性。
二、单元测试极难编写(可测试性差)
单元测试的核心要求是 “隔离依赖”:测试 getFlowItem() 方法时,应能通过 Mock(模拟)IEkuaibaoFlowClientRpc 来控制返回结果,避免依赖真实的 RPC 服务(否则测试不稳定、速度慢)。
但 SpringUtil.getBean() 是 “硬编码” 的依赖获取方式,无法通过常规手段替换依赖:
- 若使用 Mockito 等测试框架,无法将 Mock 的 IEkuaibaoFlowClientRpc 注入到 SpringUtil 中(除非修改 SpringUtil 源码,增加测试专用的 Setter 方法,这会污染生产代码);
- 为了让测试通过,可能被迫在测试环境中启动完整的 Spring 容器(加载所有 Bean),导致测试变成 “集成测试”,失去单元测试的快速、隔离特性。
三、存在 “Bean 未初始化完成” 的风险
Spring 容器初始化 Bean 是有顺序的:若 AbstractBiLawsuitFeeExtService 的子类(concrete class)初始化时机早于 IEkuaibaoFlowClientRpc,则在调用 getFlowItem() 时,SpringUtil.getBean() 会尝试获取一个尚未初始化完成的 Bean,直接抛出 NoSuchBeanDefinitionException(找不到 Bean)或 BeanCreationException(Bean 未创建完成)。
虽然在常规场景下,Spring 会保证依赖的 Bean 先初始化,但这种 “主动获取” 的方式打破了 Spring 的依赖管理逻辑,尤其是在以下场景中风险极高:
- 存在循环依赖时,Spring 的循环依赖解决机制可能无法覆盖主动获取的场景;
- 自定义了 Bean 的初始化顺序(如 @DependsOn 注解),手动获取可能跳过依赖顺序检查。
为什么不推荐优先使用 SpringUtil.getBean()?
Spring 的核心设计理念是 “控制反转(IoC)”——由 Spring 容器统一管理 Bean 的创建、依赖注入和生命周期,而非手动获取。SpringUtil.getBean() 本质是 “手动干预 IoC 容器”,若滥用会导致:
- 破坏依赖透明性:代码无法直观看出依赖关系,可读性、可维护性下降;
- 难以测试:手动获取 Bean 会绕过 Spring 的测试支持(如 @MockBean),单元测试需额外模拟容器;
- 线程安全风险:若工具类实现不严谨(如容器未初始化完成就调用),可能引发空指针或并发问题;
- 耦合容器细节:代码与 Spring 容器强绑定,脱离 Spring 环境无法运行。
因此,优先使用 @Autowired、@Resource、构造器注入等注解式注入,仅在注解无法覆盖的场景下使用 SpringUtil.getBean()。
SpringUtil.getBean() 的正确使用场景
仅在注解式注入无法实现的场景下使用,常见场景如下:
场景 1:静态方法中需要依赖 Spring 管理的 Bean
静态方法不属于对象实例,无法通过 @Autowired 注入依赖(@Autowired 作用于实例字段 / 构造器),此时可通过 getBean() 手动获取。
示例:静态工具类调用 Service
/**
* 非 Spring 管理的静态工具类(无 @Component)
*/
public class ExcelUtil {
// 静态方法需要用 UserService 处理业务
public static List<UserDTO> exportUserExcel(Long deptId) {
// 手动获取 Spring 管理的 UserService 实例
UserService userService = SpringUtil.getBean(UserService.class);
// 调用 Service 方法
List<User> users = userService.listByDeptId(deptId);
// 转换为 DTO 并返回
return users.stream().map(UserDTO::convert).collect(Collectors.toList());
}
}场景 2:非 Spring 管理的类中需要依赖 Bean
若类是通过 new 手动创建(而非 Spring 容器初始化),则无法使用注解注入,需通过 getBean() 获取依赖。
示例:手动创建的类调用 DAO
/**
* 非 Spring 管理的类(通过 new 创建)
*/
public class OrderProcessor {
private OrderDAO orderDAO;
// 构造器中手动获取 Spring 管理的 OrderDAO
public OrderProcessor() {
this.orderDAO = SpringUtil.getBean(OrderDAO.class);
}
// 业务方法:使用 DAO 操作数据库
public void processOrder(Order order) {
// 调用 DAO 保存订单
orderDAO.insert(order);
// 其他业务逻辑...
}
}
// 使用时:手动 new 实例
OrderProcessor processor = new OrderProcessor();
processor.processOrder(new Order());场景 3:Spring 初始化阶段(如 @PostConstruct 前)需要依赖
若在 Spring Bean 的初始化早期(如 static 代码块、构造器中)需要依赖其他 Bean,此时注解注入尚未完成,可通过 getBean() 兜底(但需谨慎,确保依赖的 Bean 已初始化)。
示例:Bean 构造器中获取依赖
@Component
public class CacheManager {
private RedisTemplate<String, Object> redisTemplate;
// 构造器中获取 RedisTemplate(若用 @Autowired 注入,构造器执行时注入尚未完成,会空指针)
public CacheManager() {
this.redisTemplate = SpringUtil.getBean(RedisTemplate.class);
}
// 初始化缓存(需在 redisTemplate 就绪后执行)
@PostConstruct
public void initCache() {
redisTemplate.opsForValue().set("init_flag", "true");
}
}四、使用 SpringUtil.getBean() 的核心注意事项
-
禁止在 Spring 初始化完成前调用
严禁在 static 代码块、SpringUtil 的构造器中调用 getBean()—— 此时 applicationContext 尚未注入,会触发 IllegalStateException。
安全的调用时机:容器初始化完成后(如 Web 项目的 ContextRefreshedEvent 事件后、业务方法执行时)。 -
避免用于 “循环依赖” 场景
若 A 依赖 B,B 又依赖 A,且均通过 getBean() 获取,会导致循环依赖死锁。
解决方案:优先用 Spring 原生的循环依赖支持(如构造器注入 +@Lazy,或字段注入),而非 getBean()。 -
同类型多 Bean 需指定名称
若容器中存在多个同类型的 Bean(如 @Component(“userServiceV1”) 和 @Component(“userServiceV2”)),直接调用 getBean(UserService.class) 会抛 NoUniqueBeanDefinitionException,需用 getBean(“userServiceV1”, UserService.class) 指定名称。
-
异常处理需显式
getBean() 会抛出 BeansException(如 Bean 不存在、类型不匹配),需根据业务场景捕获异常,避免直接抛出导致程序崩溃。
示例:
try { UserService userService = SpringUtil.getBean(UserService.class); } catch (NoSuchBeanDefinitionException e) { // 处理 Bean 不存在的情况(如日志告警、返回默认值) log.error("UserService 未在 Spring 容器中注册", e); throw new BusinessException("服务初始化失败"); } -
避免滥用:优先注解注入
若场景可通过注解注入解决(如实例方法、Spring 管理的 Bean),绝对不用 getBean()。例如:
错误用法:在 @Component 类的实例方法中用 getBean() 获取依赖(应直接 @Autowired);
正确用法:仅在上述 “静态方法、非 Spring 类” 等注解无法覆盖的场景使用。
无用和无意义的注释




