这篇文章是我在学习并发相关知识的时候做的笔记,现重新整理记录以备不时之需。
计算机的发展
软件技术的发展源于硬件性能的提升,从继电器到真空管到电子管到晶体管再到集成电路,我们的计算机也越来越小,我们的外设也越来越多越来越精巧。但终归逃脱不了冯诺依曼结构:计算机由 输入设备,控制器、运算器、存储器、输出设备 5部分组成,5大部分之间通过总线通信(交换信息),彼此之间协调工作共同完成计算任务。我们把 运算器和控制器 合起来叫中央处理单元,也就是CPU。我们把寄存器、内存、硬盘等具备存储功能的设备统称为存储器。不要以为通用计算机模型只有 冯诺依曼结构,计算机发展的历程中还出现过一种被称之为 哈佛结构的通用计算机模型,它与 冯诺依曼结构的不同之处仅仅在于是不是把数据和指令存储在一起,如果存储器分成数据存储器和指令存储器,那就是哈佛结构,否则就是冯诺依曼结构。哈佛结构的好处就是可以实现指令和数据处理的并行,提高计算机的处理速度,但是也更消耗空间,同时计算机的设计复杂度也会有所提高,因此哈佛结构一般用在一些高精尖的计算机设计领域,而冯诺依曼计算机结构则以其设计简单而著称,一直沿用至今。

进程、线程、协程
操作系统出现后,才有了进程的概念,有了进程才能谈及并发,因为并发一开始就是用在进程上的。操作系统把 cpu、内存、磁盘、键盘、显示器、扬声器等设备统统视为资源,一个任务总是要占用这些资源的,那多个任务总是要争用这些资源的,为了让任务并发有序的运行直至完成,操作系统需要协调各个任务如何占用资源,因此操作系统把任务封装成一个一个的进程,并设计一个唯一标识,叫进程ID。这些进程共享计算机的硬件资源,例如上面提到的cpu、内存、键盘、扬声器等。由于进程分配资源实在太宽泛了,为了把任务拆分的更细,才衍生出了线程,任务拆的越细越容易并行。至少目前为止,cpu真正具体运行的是线程,占用cpu的一定是某个进程的某一个线程。
cpu很公平,晶振按照一定的频率发出脉冲,经过倍频器之后,cpu以某个固定的频率驱动内部的元器件。按照一定的时钟周期一会儿执行A进程的a1线程,一会又执行A进程的a2线程,一会儿又去执行B进程的b1线程了,周而复始,所以cpu总是忙碌的,其他资源也都是忙碌的,这样资源就能得到很好的利用,不会有闲置的资源。由于线程切换很快所以看起来任务好像是在并行执行,cpu被多个线程以抢占的方式占用着,线程来回切换,每次切换都需要把当前线程的状态保存下来,再加载下一任务线程的状态后,继续服务于下一任务线程,所谓状态其实就是一个线程运行过程中的中间数据,那数据保存在哪儿呢?保存在内核空间,这个我们后面再讲操作系统的时候再讲什么是内核空间什么是用户空间。这个线程切换的过程我们叫线程上下文切换,如果一个线程切换到了另一个进程的线程的时候就发生了所谓的进程上线文切换,在保存线程状态的时候还要额外保存一部分进程的状态,所以进程的上下文切换比单纯的线程上下文切换更加耗时和耗费空间。要知道上下文切换是需要时间的,当频繁切换带来的耗时大于线程执行任务的耗时的时候,就得不偿失了,为了解决这一问题就发明了协程,协程其实是在一个线程里面执行的程序,只不过可以响应中断而已,本质上还是顺序执行的,放心,java早晚也会支持这种方式的。这就是进程、线程、协程在计算机上的执行方式。
总结一下
- 进程是计算机分配资源的最小单位
- 线程是cpu执行的最小单位
- 线程|进程切换我们成为上下文切换,切换的时候需要保存现场
并行、并发
并发:就是任务同时发生,但发生后并不一定能同时执行,也可能交替执行。例如在单核cpu上,多个线程就是交替占用cpu的。
并行:就是任务同时执行,这个是真正意义上的同一时刻执行多个任务。
这里咬文嚼字没有意义,以后无论说并发还是并行,你都可以笼统的理解为同时执行。
线程
线程的创建
Java 中线程的创建有两种方式,记住只有这两种方式,但是有多种写法,不过都逃不出这两种形式。
- 继承Thread类然后重写run方法,先后创建该线程子类对象。
- 实现Runnable接口然后实现run方法,然后创建该子类对象并作为参数传入Thread构造方法。
第一种方式
package main;
public class Main {
public static void main(String[] args) {
Thread thread = new MyThread();
}
}
class MyThread extends Thread{
@Override
public void run() {
//任务逻辑
}
}或者
new Thread() {
@Override
public void run() {
//任务逻辑
}
}.start();第二种
package main;
public class Main {
public static void main(String[] args) {
Thread thread = new Thread(new MyRunnable());
}
}
class MyRunnable implements Runnable {
@Override
public void run() {
//任务逻辑
}
}但是我一般的写法习惯用Java的函数式写法,包括后面的示例代码,我都会大量使用Java的λ表达式。
package main;
public class Main {
public static void main(String[] args) {
Thread thread = new Thread(()->{
//任务逻辑
});
}
}上面两种方法无论是继承Thread类然后重写run方法,还是实现Runnable接口的run方法,两种方式都有一个共同点那就是run方法是没有返回值的。这就是说当年Java设计线程的时候就没有考虑过一个线程还有返回值的情况,当年的作者认为一个任务就应该完全在一个线程内执行结束,中间执行的结果不应该逃逸到线程之外,如果一个线程要等另一个线程的话,就用通知的方式或共享变量的方式通信就好了。但是后来发现需要有返回值的情况,但是没办法,Thread这时候已经设计出来了,就是没有返回值的,改也改不了了,那怎么办呢?搞了Future + Callable = FutureTask , Future 的意思就是未来,也就是说未来可能会有某个值,我现在不用,一会儿可能会获取。
以上是最基本的创建线程的写法,肯定会有人问用哪种方式好呢? 无论你回答哪种方式好我觉得都不合适,我们在决定使用哪种方式的时候一定不能脱离实际。我们在技术选型的时候也一样,不能脱离业务背景。
这里就涉及到继承和实现接口两种方式的优缺点对比了。
- 因为JAVA是单根继承的语言,不支持多个父类,因此如果一个类已经继承了Thread就不太好扩展其他能力了,但是既然已经继承了Thread类,那这个类大概率跟线程有关,貌似与不需要在继承其他类了。
- 使用实现Runnable的方式看似还比较灵活一点,但是又能灵活到哪里去呢。
- 用λ的形式写的更优雅一点,不用到处定义类,但貌似只能在一个地方使用一次,可能跨类了就得在重新写一遍,要是给它定义到外边又感觉不够OOP了。
线程的启动
start() vs run()
线程在Java中被视为一个对象,我们new 一个Thread对象的时候,该Thread对象实例会和操作系统的一个轻量级线程一一对应。Java在线程的实现方面完全依赖了操作系统的线程实现,每new 一个线程对象都会向操作系统申请创建一个系统级别的线程。我们可以看到,在Java Thread类的前几行有一个 static 的静态代码块,类加载的时候会先加载一下 registerNatives 方法。
public
class Thread implements Runnable {
/* Make sure registerNatives is the first thing <clinit> does. */
private static native void registerNatives();
static {
registerNatives();
}
.....
}该native的registerNatives方法的目的就是将Java 线程对象中的方法同操作系统线程的方法进行一一绑定。其中run方法也就是线程执行的任务被绑定到了操作系统的run方法上,当操作系统线程开始执行的时候其实就是执行的Java线程的run方法。
我们创建好线程对象之后必须得通知操作系统该线程可以执行了,用的就是 start() 这个函数。所以 start()并不是执行 run() 函数里面的代码,而是通知操作系统你需要在合适的时间分配资源来执行run里面的代码,至于具体什么时候执行,就看操作系统心情了。运行线程是需要内存空间的,有一部分内存空间在创建线程的时候就开始分配了,后面会讲 程序计数器、栈、本地方法栈、堆、方法区的时候还会提及。
Java 语言是如何实现线程的呢?
Java 语言的线程实现是依托于JVM帮忙实现的,JVM是什么?JVM 是Java的虚拟机。我们说启动应用其实说白了启动了一个JAVA虚拟机进程而已。我们的应用都是跑在虚拟机里面的。
那Java为什么要搞一个JVM出来了,因为Java说我要跨平台,我要一次编写到处编译随处运行。那怎么做呢,针对不同的平台实现不同的虚拟机即可。那JVM是怎么实现一个Java线程的呢?首先主流操作系统都会有一套自己的进程、线程实现方案,然后提供出来。以hotspot虚拟机为例子,为了偷懒,直接使用了操作系统的线程实现,什么意思呢,那就是一个Java线程其实底层就是一个操作系统线程,他们两个是一一映射的。那你说的这不是废话么。这还真不是废话,没人说一个线程一个对应一个操作系统线程,还有自己实现的呢,还有n:1 和 n:m 的呢。要知道Jvm规定的是一个Java线程一一对应一个操作系统线程,我们称为1:1比例模型。但是不是所有语言都是这么设计的。例如go语言的线程和操作系统线程就是m:n的关系,也就是go的m个线程可以由n个操作系统线程共同完成,其目的是达到复用,它是一种多对多的关系。
线程的状态流转
前面说到,一个线程在start()后只是通知操作系统,我这个线程交给你了,你可以运行了。我们看看start方法
public synchronized void start() {
/**
* This method is not invoked for the main method thread or "system"
* group threads created/set up by the VM. Any new functionality added
* to this method in the future may have to also be added to the VM.
*
* A zero status value corresponds to state "NEW".
*/
if (threadStatus != 0)
throw new IllegalThreadStateException();
/* Notify the group that this thread is about to be started
* so that it can be added to the group's list of threads
* and the group's unstarted count can be decremented. */
group.add(this);
boolean started = false;
try {
start0();
started = true;
} finally {
try {
if (!started) {
group.threadStartFailed(this);
}
} catch (Throwable ignore) {
/* do nothing. If start0 threw a Throwable then
it will be passed up the call stack */
}
}
}首先我们注意到这个方法是synchronized修饰的,目的就是防止并发情况下的start. 另外注意,里面有个判断 if (threadStatus != 0) throw new IllegalThreadStateException();
如果连续两次start,第二次start肯定会报错,就是因为 threadStatus !=0 了。0代表初始状态,start后就变成其他状态了。
那一个线程都有哪些状态,以及状态机是怎么转换的呢?一切都在源码当中
/**
* A thread state. A thread can be in one of the following states:
* <ul>
* <li>{@link #NEW}<br>
* A thread that has not yet started is in this state.
* </li>
* <li>{@link #RUNNABLE}<br>
* A thread executing in the Java virtual machine is in this state.
* </li>
* <li>{@link #BLOCKED}<br>
* A thread that is blocked waiting for a monitor lock
* is in this state.
* </li>
* <li>{@link #WAITING}<br>
* A thread that is waiting indefinitely for another thread to
* perform a particular action is in this state.
* </li>
* <li>{@link #TIMED_WAITING}<br>
* A thread that is waiting for another thread to perform an action
* for up to a specified waiting time is in this state.
* </li>
* <li>{@link #TERMINATED}<br>
* A thread that has exited is in this state.
* </li>
* </ul>
*
* <p>
* A thread can be in only one state at a given point in time.
* These states are virtual machine states which do not reflect
* any operating system thread states.
*
* @since 1.5
* @see #getState
*/
public enum State {
/**
* Thread state for a thread which has not yet started.
*/
NEW,
/**
* Thread state for a runnable thread. A thread in the runnable
* state is executing in the Java virtual machine but it may
* be waiting for other resources from the operating system
* such as processor.
*/
RUNNABLE,
/**
* Thread state for a thread blocked waiting for a monitor lock.
* A thread in the blocked state is waiting for a monitor lock
* to enter a synchronized block/method or
* reenter a synchronized block/method after calling
* {@link Object#wait() Object.wait}.
*/
BLOCKED,
/**
* Thread state for a waiting thread.
* A thread is in the waiting state due to calling one of the
* following methods:
* <ul>
* <li>{@link Object#wait() Object.wait} with no timeout</li>
* <li>{@link #join() Thread.join} with no timeout</li>
* <li>{@link LockSupport#park() LockSupport.park}</li>
* </ul>
*
* <p>A thread in the waiting state is waiting for another thread to
* perform a particular action.
*
* For example, a thread that has called <tt>Object.wait()</tt>
* on an object is waiting for another thread to call
* <tt>Object.notify()</tt> or <tt>Object.notifyAll()</tt> on
* that object. A thread that has called <tt>Thread.join()</tt>
* is waiting for a specified thread to terminate.
*/
WAITING,
/**
* Thread state for a waiting thread with a specified waiting time.
* A thread is in the timed waiting state due to calling one of
* the following methods with a specified positive waiting time:
* <ul>
* <li>{@link #sleep Thread.sleep}</li>
* <li>{@link Object#wait(long) Object.wait} with timeout</li>
* <li>{@link #join(long) Thread.join} with timeout</li>
* <li>{@link LockSupport#parkNanos LockSupport.parkNanos}</li>
* <li>{@link LockSupport#parkUntil LockSupport.parkUntil}</li>
* </ul>
*/
TIMED_WAITING,
/**
* Thread state for a terminated thread.
* The thread has completed execution.
*/
TERMINATED;
}看到没只有6中 NEW(新建)、RUNNABLE(可运行)、BLOCK(阻塞)、WATING(等待)、TIME_WATING(限时等待)、TERMINATED(结束). 注意这六中只是JVM中一个线程所处的状态,可不代表操作系统线程的状态,例如对于操作系统来说 RUNABLE 对应两种一种叫 READY 一种叫 RUNNING。
一个线程的生命周期始于 NEW 终于 TERMINATED. NEW 之后经过start() 变成 RUNNABLE 可运行状态。注意可运行并不一定在运行,必须得等操作系统真正分配时间片段后才算真正的运行,所以看到RUNNABLE状态的线程可能在运行也可能在等待运行,区分不出来的,这个算是JAVA线程设计的一个败笔吧。
这几个状态中,最难理解的就是 BLOCK 和 WATING 、TIME_WATING 明明都是被阻塞住了,当前程序都不再往下执行了,为啥要区分呢?
BLOCK
BLOCK 一定在获取锁的时候获取不到才会BLOCK
获取不到锁的线程一定被阻塞,直到另一个获取锁的线程执行完成同步代码后释放锁才得以解脱,释放锁的时候会唤醒阻塞在该锁上的其他线程,其实就是 notify 或notifyAll. 只不过是操作系统执行了这个动作而已。所谓的notify 或 notifyAll 和start一样只不过是把状态变成RUNNABLE而已.
/**
* Thread state for a thread blocked waiting for a monitor lock.
* A thread in the blocked state is waiting for a monitor lock
* to enter a synchronized block/method or
* reenter a synchronized block/method after calling
* {@link Object#wait() Object.wait}.
*/上面 reenter a synchronized block/method after calling {@link Object#wait() Object.wait}.该怎么理解呢。
翻译过来是 调用object.wait方法后重入同步代码块的时候会变成 Block状态。按理说调用Object.wait后应该变成WATING状态啊,怎么这这里又变成BLOCK状态了呢?按照我的理解,调用Object.wait方法后当前线程先变成了WATING状态.当他被唤醒后先变成RUNNABLE状态,轮到他执行的时候,发现需要先获取到锁资源才行,于是该线程重新征用锁,也就是重入的时候,如果获取到锁则向下继续执行如果获取不到所则进入BLOCK状态。
WATING
WATING 一定在等另一个线程执行完某个操作,WATING状态一定得有人叫醒才行。这是线程之间的一种通信方式,称之为通知,还有一种方式叫共享内存,后面会继续讲解。
{@link Object#wait() Object.wait} with no timeout
当调用不加时间的wait方法的时候。注意这里要想调用wait方法一定得先获取到对象对应的锁。获取不到锁进入阻塞状态,获取到锁后再调用wait方法,这时候直接进入WAITING状态。
{@link #join() Thread.join} with no timeout
把一个线程加到当前线程的执行流程中,也就是在join那个时间点等待执行线程的完成,完成后才继续执行,所以这是时候当前线程是处于WATING状态的,这个地方等待的是另一个线程执行完成
Join 方法:本质上还是根据wait方法实现的。分析join源码发现join方法本身是使用了synchronized修饰符的,锁对象是等待的那个线程,获取到锁后立马执行了wait方法,这样当前线程就处于waiting状态了,待等待的线程执行完成操作系统会先唤醒所有等待在该线程上的其他线程。(所谓唤醒,其实就是把状态改为RUNNABLE)
{@link LockSupport#park() LockSupport.park}
可见等待状态其实与锁无关,它的唤醒一定是另一个线程完成某件事情后主动去唤醒
TIME_WATING
一定在等另一个线程执行完某个操作,并且一定有时间限制,不会一直傻等。其实现原理是,操作系统有一个时钟,可以向该时钟注册事件,在这里就是注册一个唤醒该线程的事件,等时间到了,系统时钟向操作系统发起中断,然后唤醒被挂起的线程,这是硬件中断,操作系统一定会响应的,所以TIME_WATING状态的线程往往唤醒的比较及时。
线程通信
上面说的 wait\notify\notifyAll 以及 synchronized 还有 LockSupport的park\unpark 其实都是用在多线程之中的,其目的都是为了进行线程间的通信。所谓线程通信指的就是一个线程的运行状态或中间结果可以被其他线程感知。线程间通信的方式主要有 共享内存方式(包括共享磁盘、共享缓存等)、通知机制、还有管道的方式。线程间的通信方式主要参考的是进程间的通信方式实现的。进程间的通信方式比较多,包括 管道、有名管道、共享内存、共享存储、消息队列、信号、信号量。
初识进程间通信
管道
管道是进程间通信的一种方式,这种进程间通信方式只适用于父子或兄弟进程之间,他的特点是是一端进一端出,管道满的时候写不进去被阻塞,管道空的时候读不出来被阻塞。
我先举一个例子来直观的感受一下,我们常常使用下面的shell命令 ps -ef|grep java 。这条命令指的是我们将ps进程的标准输出结果传给给grep进程。我们通过 | 这个符号就可以连接起左右两个进程。
有名管道
上面说的管道,也叫匿名管道,因为他没有名字,其本质是在内存开辟一个空间,然后一个进程的输出先写到这个内存空间,然后操作系统再把这个内存空间的值传递给另一个进程。但是有名管道不同,有名管道其实是文件系统的一部分,因为他有名字,对外看起来就是一个文件。
shell 中使用mkfifo 命令创建一个有名管道。
消息队列
消息队列,是消息的链表,存放在内核中。一个消息队列由一个标识符(即队列ID)来标识。
共享内存
共享内存(Shared Memory),指两个或多个进程共享一个给定的内存存储区。
共享存储
区别于内存的一种共享形式,例如一个进程写文件一个进程读文件,文件当然是存储在磁盘上的,所以是共享磁盘了。如果一个进程网u盘里写一个从U盘里读那就是共享u盘了。
socket通信|http通信
两个机器之间进程的通信
信号
信号机制是类UNIX系统中的一种重要的进程间通信手段之一。我们经常使用信号来向一个进程发送一个简短的消息。
信号量
信号量用于实现进程间的互斥与同步,而不是用于存储进程间通信数据,可以理解为锁标志。
事实上,进程也不知道信号到底什么时候到达。信号是异步的,一个进程不可能等待信号的到来,也不知道信号会到来,那么,进程是如何发现和接受信号呢?信号的接收不是由用户进程来完成的,而是由内核代理。当一个进程P2向另一个进程P1发送信号后,内核接受到信号,并将其放在P1的信号队列当中。当P1再次陷入内核态时,会先检查信号队列,并根据相应的信号调取相应的信号处理函数。
信号检测和响应时机刚才我们说,当P1再次陷入内核时,会检查信号队列。那么,P1什么时候会再次陷入内核呢?陷入内核后在什么时机会检测信号队列呢?
- 当前进程由于系统调用、中断或异常而进入系统空间以后,从系统空间返回到用户空间的前夕。
- 当前进程在内核中进入睡眠以后刚被唤醒的时候(必定是在系统调用中)
主要应用是kill. kill的时候给进程发送一个信号,下一次cpu再次调度到进程的时候都是先查询信号列表,如果有,则优先响应信号中断。这是软中断的一种,因此是有延迟的。只有等到下一个cpu调度到的时候才会执行。
线程通信
通知机制
Object.wait 你可以理解为在哪个线程中调用某个对象的wait方法,其实就是把这个线程挂到该对象的等待区中。一旦其他线程里面调用了该对象的notify或notifyAll方法就会到该对象的等待区里面唤醒一个或全部的线程。那这个对象肯定得是共享对象,由于要调用某个对象的wait一定要先锁定该对象,因此可以理解为先获取该对象的锁,然后才能wait和notify。如果没有获取到锁就调用wait或notify就会抛出 java.lang.IllegalMonitorStateException: current thread is not owner异常。
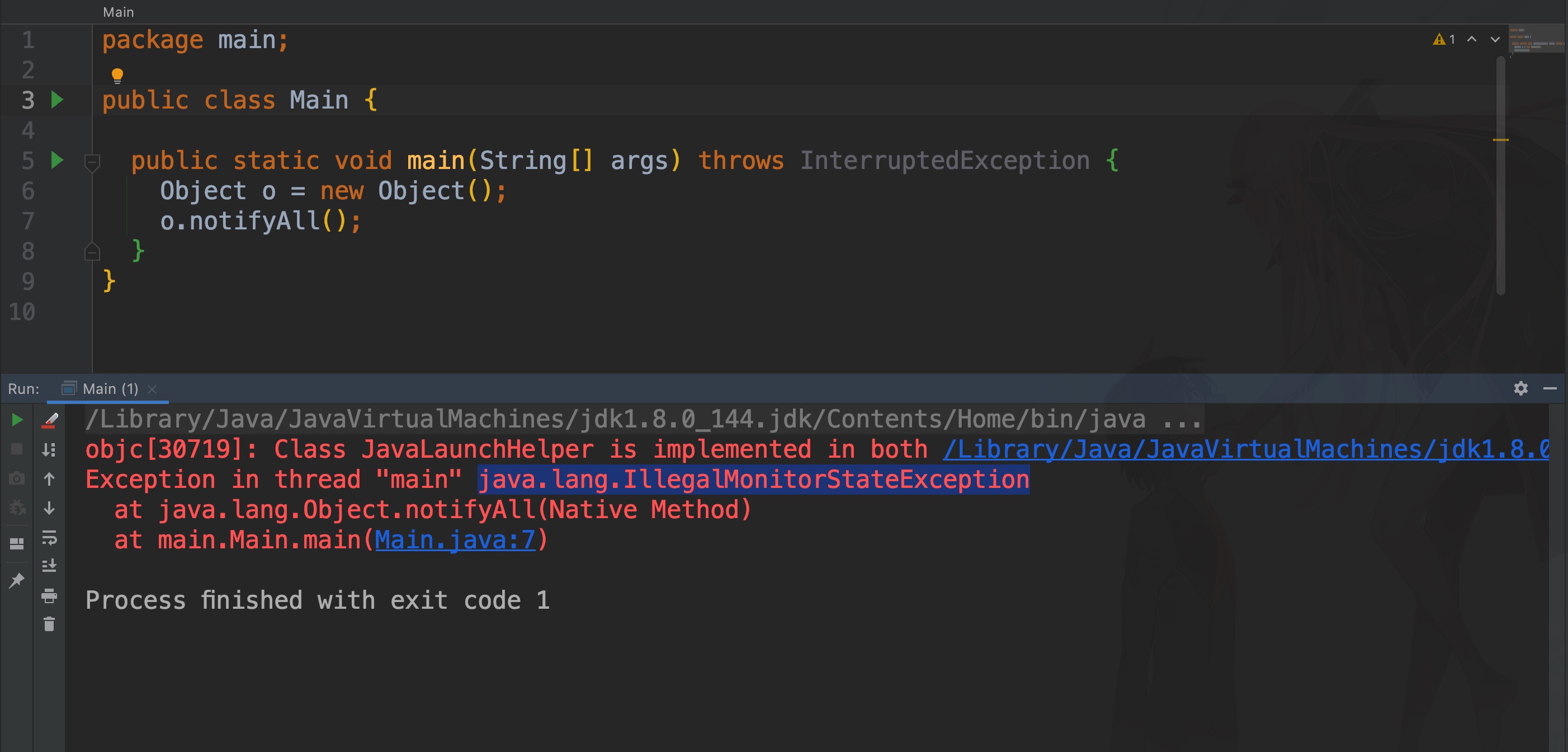
共享内存
如果多个线程持有同一个变量,或者说对同一块内存是可见的,那么一个线程对这块内存的变化天然的就能被另一个线程所感知,这样就能实现线程间的通信了。看似简单,但是由于JVM规范的存在,每个线程都是工作在自己的工作空间上的,也就是说对于共享变量,每个线程都会持有该变量的一份拷贝。那这样就会有可见性的问题,一个线程对共享变量的修改,不能及时的反馈到另一个线程里面。
为了解决这个问题 voliatle 应运而生。
volatile 关键字
可见性
上面说到了变量的可见性问题。变量的可见性指的是一个线程修改了一个变量成功之后,另一个线程能不能立马看到这个修改后变量的值。如果不能看到,那就叫做存在可见性的问题。就会导致运行结果与预期不同。
这类问题一定出现在多线程共享内存的时候,单线程内代码是从上到下依次解释执行的不存在可见性问题。网上很多人都在讲什么cpu架构、什么缓存一致性协议OMEI 其实跟 volatile 没有半毛钱关系。那个是cpu在有多级缓存的时候如何保证共享内存在多个缓存中的一致性的。跟voliatle 解决的根本不是一个问题。
共享变量的可见性问题产生的原因是由于JVM规定,线程运行有自己的内存空间,先把变量都缓存一份到自己的运行空间,之后所有的操作都是在自己运行空间里面玩,至于修改后的变量什么时候同步到实际的内存则视情况而定,这种方式我们称之为写回,也就是写完自己的运行空间的变量就认为操作成功了。这就造成了内存可见性问题。volitale 就是为了解决这样的问题,其原理也很简单,就是把共享变量变成看起来只有一份,其本质是把共享变量的写回变成写穿,然后通知其他缓存了该共享变量的线程缓存失效。
{
"translation": [
"挥发性"
],
"basic": {
"us-phonetic": "ˈvɑːlətl",
"phonetic": "ˈvɒlətaɪl",
"uk-phonetic": "ˈvɒlətaɪl",
"explains": [
"n. 挥发物;有翅的动物",
"adj. [化学] 挥发性的;不稳定的;爆炸性的;反复无常的",
"n. (Volatile)人名;(意)沃拉蒂莱"
]
}
}volitale 的意思是挥发性引申为不稳定的易失的,所以被他修饰的变量很不稳定,那就得每次读之前去主内存里面读,每次写之后都要同步到主内存。
这个可见性问题说是好验证,无非就是一个线程修改一个共享变量的值之后,另一个线程看不到就行,但由于线程运行的非常快且不可控,真要你写一个示例出来,你还真不见的能写对。
package main;
import java.util.concurrent.TimeUnit;
public class Main {
public static boolean keepRunning = true;
public static void main(String[] args) {
Thread thread1 = new Thread(() -> {
//这个地方等1秒钟的目的是为了线程2先把共享变量缓存进自己的内存空间
//如果这个地方太快,很可能线程2来不及缓存
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
keepRunning = false;
System.out.println("keep running false");
});
Thread thread2 = new Thread(() -> {
while (keepRunning) {
//System.out.println("running"); 这个地方千万不要加这个输出,否则你会发现程序的表现与预期不符
//程序的预期是 线程1 修改keepRunning 的值为false后,理论上线程2应该停止,但是运行结果却不是
//说明线程1对共享变量的修改对线程2其实是不可见的
}
System.out.println("exit");
});
thread1.start();
thread2.start();
}
}这里共享变量加上volatile修饰就可以解决,证明volatile可以解决共享变的可见性问题。那他是怎么解决可见性的问题的呢?
volatile究竟如何让变量的修改在多线程之间可见的呢
所有对volatile变量的操作翻译成会变之后,都会加一个lock指令,这个lock指令是一个cpu原语,可以保证变量在变化后立马写入主存,也能保证在读取数据的时候每次都去主内存中读取,就好像过线程之间从来没有缓存过变量的拷贝一样。
注意也仅仅是解决可见性问题,并不能保证变量操作的原子性,操作的原子性只能用cas或锁来解决。
volatile还有一个附带的功能,就是防止指令重排序。在单线程里面,指令爱怎么排序怎么排序,反正也不影响最后的执行结果。指令重排序并不会引起变量的可见性的问题,但是在多线程里面如果对共享变量的操作被重排序了,就有可能导致结果的不确定性。例如 按照道理说,变量的初始化和赋值是先初始化,初始化完了之后才把引用指向该对象,但是有可能cpu先让指针指向了一个未初始化好的内存区域,这时候如果其他线程使用了该共享变量那就有可能发生问题。典型问题就是单例中的DCL,想要写好还真不容易。
指令重排序
要说volatile可以解决内存可见性问题,是因为把写回机制变成了写穿机制并且是其他缓存失效,没有问题。那指令重排序是啥。指令重排序和可见性一样很难复现。
指令重排序有两种,一种是编译级别的指令重排序,一种是cpu级别的指令重排序。
编译级别的指令重排序
在我们无感知的情况下,我们编程的字节码就会对我们写的java指令进行一波指令重排序,这是编译优化器干的好事,因为我们写的代码总是按照人的思维去写的,但是JVM编译的时候是按照计算机的思维去编译的,这样有些情况下,JVM认为我可以优化你的指令,例如可以合并执行,可以乱序执行等等。
cpu级别的指令重排序
字节码也依然是人写的代码,cpu在执行的时候也不傻,也会优化字节码指令,也可以合并执行,可以乱序执行等等。
举个例子
bit a=0;
bit b=0;上面这条语句在编译成JAVA字节码的时候,可能就变成了 b=0 在前,a=0 在后了。
cpu执行的时候,可能 a和b 是一起赋值的,因为一条总线可以传输64位数据,可能a\b所在的内存会同时充电赋值。当然也可能先给b赋值然后再给a赋值
复现指令重排序
指令重排序和可见性一样很难复现。
package main;
public class Main {
private static int x = 0, y = 0, a = 0, b = 0;
public static void main(String[] args) throws InterruptedException {
int i = 0;
while (true) {
i++;
x = 0;y = 0;a = 0;b = 0;
Thread thread = new Thread(() -> { a = 1;x = b; });
Thread thread1 = new Thread(() -> { b = 1;y = a; });
thread.start();thread1.start();thread.join();thread1.join();
if (x == 0 && y == 0) {
System.out.println("第" + i + "次发生了指令重排序");
break;
}
}
}
}上面这段代码可以验证指令重排序的存在
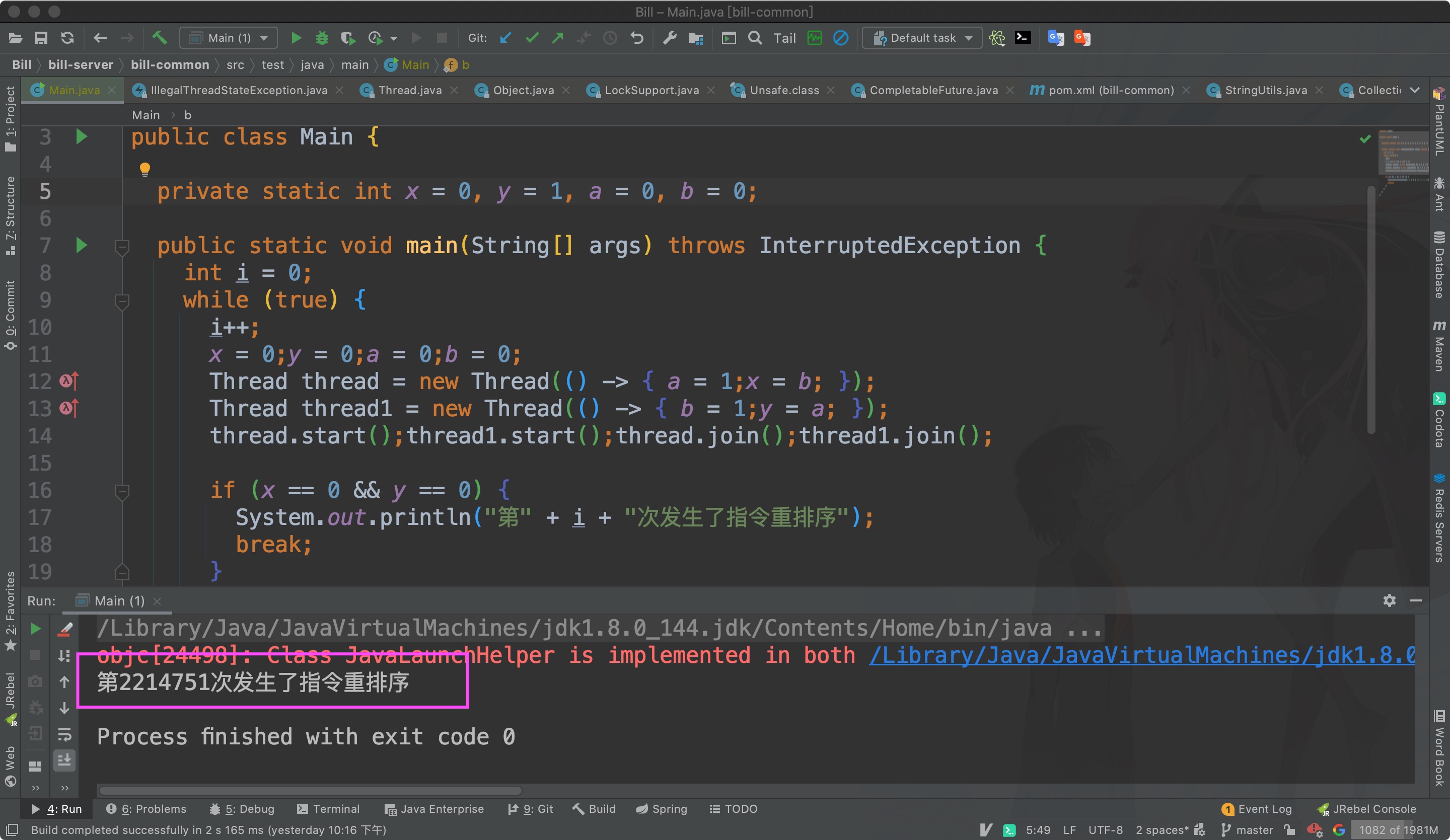
这个语义叫 as-if-serial 这个原则叫 happens-before原则
as-if-serial 语义
as-if-serial 语义的意思是,如论你编译器和cpu怎么优化我的代码,我代码执行的时候必须看起来像是串行的。有了这个保证,我们就可以放心大胆的写我们的代码,优化不是我们关心的事情。但是我们还是要了解一下as-if-seria 语义是咋实现的呢?万一面试问到呢?这个东西只是为了让你在写代码的时候不用考虑重排序的问题,你想想,你写代码的时候有特地想过某个共享变量会从排序么。很少吧。
As-if-serial语义的意思是,所有的动作(Action)都可以为了优化而被重排序,但是必须保证它们重排序后的结果和程序代码本身的应有结果是一致的。Java编译器、运行时和处理器都会保证单线程下的as-if-serial语义。 比如,为了保证这一语义,重排序不会发生在有数据依赖的操作之中。
为了保证as-if-serial 语义有了下面8条原则。如果面试问道这些,纯粹是为了秀技或者刁难你,问这些完全没有意义。都是定义不必死记。
happens-before原则
根据Java内存模型中的规定,可以总结出以下几条happens-before规则。Happens-before的前后两个操作不会被重排序且后者对前者的内存可见。
- 程序次序法则:线程中的每个动作A都happens-before于该线程中的每一个动作B,其中,在程序中,所有的动作B都能出现在A之后。
- 监视器锁法则:对一个监视器锁的解锁 happens-before于每一个后续对同一监视器锁的加锁。
- volatile变量法则:对volatile域的写入操作happens-before于每一个后续对同一个域的读写操作。
- 线程启动法则:在一个线程里,对Thread.start的调用会happens-before于每个启动线程的动作。
- 线程终结法则:线程中的任何动作都happens-before于其他线程检测到这个线程已经终结、或者从Thread.join调用中成功返回,或Thread.isAlive返回false。
- 中断法则:一个线程调用另一个线程的interrupt happens-before于被中断的线程发现中断。
- 终结法则:一个对象的构造函数的结束happens-before于这个对象finalizer的开始。
- 传递性:如果A happens-before于B,且B happens-before于C,则A happens-before于C
这个只是一个法则,可以说是一个协议,一个口头约定,每一条法则都是要有对应的实现的,至于具体怎么实现,不同的虚拟机会有不同的方式方法。就拿volatile这关键字来说,底层使用了lock指令实现的,至于lock指令是怎么实现的,如果面试问到了,你就说不知道就行了。真没必要在深挖了,再挖就挖到电路怎么设计了。
防止指令重排序的方法
既然操作系统提供了指令重排序的手段,为了解决命令执行的效率,那就必须提供关闭这个功能的方式,因为总有一些场景我们是不需要也不能让其发生重排序的。这就是内存屏障,内存屏障就可以告诉编译器或者cpu地方你不能给我重排序,否则我就挂了。
防止指令重排序的方法是加入一道内存屏障,就好像一堵墙,这个墙就规定了墙两边的指令无论如何都不能发生指令重排序,但是同一边的指令再怎么排就怎么排。如果墙的一边是写,一遍是读,那意思就是必须写完才能读,这样读到了一定是写完后的值,而不是写之前的值。
volatile 只能解决可见性问题,但是解决不了原子性问题?那原子性问题怎么解决呢,只能用更强大的工具了那就是锁。注意锁是一个很大的概念。Java中就是 synchronized 关键字以及Lock接口和其各种子类的实现的锁。
锁
在同一程序中运行多个线程本身不会导致问题,问题在于多个线程访问了相同的资源。如,同一内存区(变量,数组,或对象)、系统(数据库,web services等)或文件。实际上,这些问题只有在一或多个线程向这些资源做了写操作时才有可能发生,只要资源没有发生变化,多个线程读取相同的资源就是安全的。
为什么需要锁
我们把多个线程竞争处理的资源称为临界资源(代码块、方法体等),当一个线程获得了临界资源的使用权以后,为了保证临界资源在同一时间只能由一个线程获得,其它线程必须等这个线程处理完以后才能通过竞争再次尝试获得临界资源的使用权。我们抽象出来了锁这种东西。
追问:为什么要保证临界资源在同一时间只能由一个线程使用?
首先肯定是有这样的场景存在,多个线程同时操作临界资源会导致数据的不一致。
追问:什么叫数据的不一致?
就是你本来期望是一个结果,但是偏偏变成了另一个结果,本来不应该出现的情况,但是偏偏出现了,就叫数据不一致了。
追问:所以归根结底是为了解决临界资源在并发使用过程中可能出现的数据不一致性问题才必须保证临界资源在同一时间只能由一个线程获得?
是的。因为并发会导致数据不一致,那干脆在使用临界资源的时候不要并发了,多么简单粗暴啊。
追问:说了半天还是没有说到锁啊?
那我们如何实现上面说的 必须保证临界资源在同一时间只能由一个线程获得呢?答案就是大家对向某个人提出申请,这个人必须足够公正,能保证在同一时间只能有一个人获得申请,而且要保证获得申请的人不撤销申请其他人即使再申请也不会获得申请,这个人就是操作系统,这个申请就是锁,申请被统一就叫获得了锁,申请被拒绝,就是没有获得锁。而这个锁,也是一种临界资源,也要保证获取锁的这个动作的线程安全,难道为了保证获取锁的动是线程安全的就要在为获取锁的动作加一把锁么,貌似死循环了。但这个保证是操作系统保证的,请确切的说是操作系统的内核保证的,操作系统毕竟也是一个软件,他要能保证,还得依赖底层硬件能够提供这样的能力,也就是物理层面的互斥锁。
锁的分类
锁并不是某个语言特有的,c语言也有锁,c++也是,包括一些后现代的编程语言例如scala、groovy等都有锁,操作系统更需要锁,redis有锁,数据库有锁,分布式系统有分布式锁。锁你可以理解为一个工具类,使用这个工具类可以保证临界资源在同一时间只能由一个线程获得。锁的种类有很多,真的很多,有悲观锁、乐观锁,有互斥锁、共享锁,有可重入锁、不可重入锁,数据库有行锁、表锁、页锁,分布式有分布式锁,可以用redis实现可以用zookeeper实现。按照我的理解和记忆方案,不见得是对的,但在这里提出来,大家一起讨论一下。
本质上锁就分成两类,一类叫乐观锁,一类叫悲观锁,至于有些人任务乐观锁不教锁,这个观点我们就不争论了,都是定义不必死记。乐观锁的底层原理逃不出我们上面说的CAS理论,它属于无锁编程领域的一项手段。
而悲观锁才是实时在在的锁,而悲观锁有四个特性 是否公平、是否可重入、是否能响应中断、共享还是互斥。每一类锁都有这四个特性,例如 synchronized 实现的锁,的全称应该叫 :公平的可重入的不可响应中断的互斥锁。 而 ReentrentLock 实现的锁(有个参数可以控制new出来的是不是公平锁)的全称应该叫 公平的的可重入的能响应中断的互斥锁 或者 叫不公平的可重入的能响应中断的互斥锁。ReadWriteLock 的全称应该叫公平的可重入的能够响应中断的共享锁。
说明一下,共享锁一定不是单独出现,一定得分成读锁和写锁,单独的共享锁或者叫读锁,跟没加锁是一样的效果。上面说了 synchroinzed 和 Lock 。我们引出Java中的锁。
Java中的锁
Java中的乐观锁
Java 中的乐观锁 就是 Unsafe 类中各种CAS操作,使用场景就是各种 原子类们。AtomicInteger\AtomicBoolean 等等,以及 LongAdder 这类新式的自家操作,他们内部没有使用所谓的synchronzied包裹临界区,也没有使用各种Lock的子类来实现。
乐观锁只需要掌握CAS 以及 如何解决CAS的ABA问题就好。
CAS
CAS 就是 compareAndSwap 比较并交换,这个对应到汇编指令 叫 cmpXchg , 在改变值的时候,先取出当前内存里面的值,然后执行操作改变内存的值,只是在改变的时候比较一下内存中的值和我们先前取出来的值是不是一样,如果一样就说明中间没有人改过,如果不一样就说明中被人改过,这时候要么返回false 要么抛出异常,等外接捕获到异常或者失败后,是重试也好,是重新计算也好。要知道只要是先出去来然后比较最后根据比较的结果在做某项处理的时候一定会发生并发问题,有可能你出去来的值立马被其他线程改掉了,你拿到的就是过期的值了。因此必须要保证比较并交换是一条指令。
/**
* Atomically adds the given value to the current value of a field
* or array element within the given object {@code o}
* at the given {@code offset}.
*
* @param o object/array to update the field/element in
* @param offset field/element offset
* @param delta the value to add
* @return the previous value
* @since 1.8
*/
@IntrinsicCandidate
public final int getAndAddInt(Object o, long offset, int delta) {
int v;
do {
v = getIntVolatile(o, offset);
} while (!weakCompareAndSetInt(o, offset, v, v + delta));
return v;
}底层有一个native的方法
/**
* Atomically updates Java variable to {@code x} if it is currently
* holding {@code expected}.
*
* <p>This operation has memory semantics of a {@code volatile} read
* and write. Corresponds to C11 atomic_compare_exchange_strong.
*
* @return {@code true} if successful
*/
@IntrinsicCandidate
public final native boolean compareAndSetInt(Object o, long offset,int expected,int x);CAS 的原理 跟 volatile 的原理是一样的,所有的CAS操作 和 被volatile修饰的变量 翻译成底层汇编指令后都会被加上一个lock指令,这个lock指令是一个cpu原语,这个指令可以理解为cpu级别的锁,要不怎叫 lock指令呢。lock 指令可以保证后面的操作变成原子的操作中途不会被打断,也能保证后面的操作用到的内存被立即写回主存,读取都从主存中读取。
Java 中的悲观锁
Java 中的锁分两大类,一类是依靠关键字实现的自动锁,一类是实现Lock接口而生的手动锁。
synchronized
用法
实现原理
锁升级
Lock
未完待续


